及遇智悦
数据和智能驱动的精准医学
知识整合是将海量分散的生物医学信息转化为结构化、系统化且计算机可读知识的过程。生物医学知识整合存在着知识海量且碎片化、来源多样异质性强等难点和挑战。结合最新的AI技术发展,生物医学知识整合近年来取得了重大的突破。
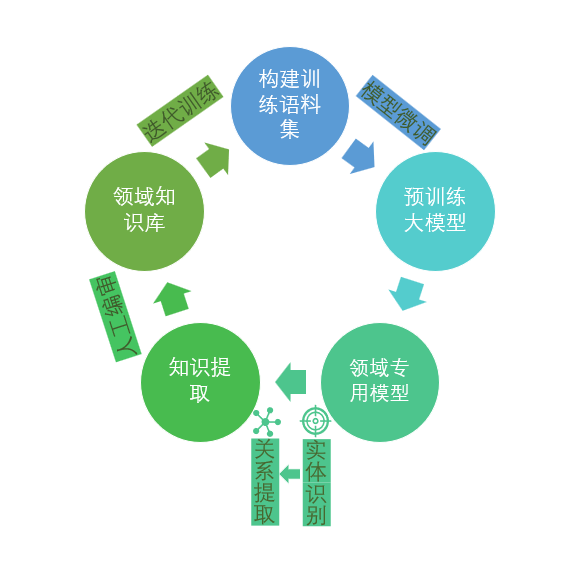
我们构建了本体—大语言模型—知识图谱相结合的生物医学知识整合框架,并已开发了基于大语言模型的知识提取算法和生物医学知识图谱BMKG,并可基于GraphRAG技术结合知识图谱和大语言模型,提供智能化的知识检索应用。
知识图谱(KG)和大语言模型(LLM)都是用于表示和利用知识的人工智能技术,旨在使机器能够理解、存储和运用知识。
以图结构存储知识的数据库,其中节点代表实体(概念),边代表实体之间的关系。
基于深度学习的自然语言处理模型,通过学习海量文本数据中的统计规律来理解和生成自然语言。
我们开发的技术流程可高效、准确地从海量文献中提取知识,具体步骤如下:
算法与应用:尿液生物标志物数据库构建,点击跳转
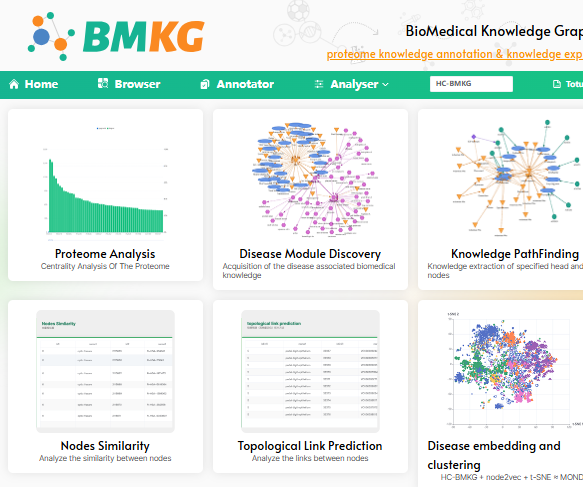
我们与中国医学科学院基础医学研究所合作构建了大规模生物医学知识图谱(BMKG),该图谱涵盖疾病、表型、基因、蛋白、通路、药物、人体解剖结构等九大类实体,包含250余万个节点和超过2500万条关系。
基于BMKG,并整合特定领域知识库和图谱,可为垂直领域的知识整合与发现提供强大支持。
graphRAG技术流程